Archer 3.1
Project coordinators 2004-2008: Marianne Hundt (Project manager, then University of Heidelberg) and Nadja Nesselhauf (Corpus manager, University of Heidelberg)
Time of compilation: 2004–2006
Language: English (British and American)
Size: 1,789,309 words
Samples: 955
Period: 1650–1999
Version: 2006
Funding information
The following consortium members provided new text during the compilation of ARCHER 3.1: Bamberg, Freiburg, Heidelberg, Helsinki, Michigan. They would like to thank the host institutions for supporting the project financially.
Compilers
The consortium members for the phase 2004-2006 were
- USA: Department of English, Northern Arizona University (Douglas Biber), Department of Linguistics; University of Southern California (Edward Finegan), Department of English; University of Michigan (Richard Bailey, Anne Curzan, Chris Palmer).
- Finland: Department of English, University of Helsinki (Matti Rissanen, Arja Nurmi).
- Sweden: Department of English, Uppsala University (Merja Kytö).
- Germany: Department of English, University of Freiburg (Christian Mair, Bernd Kortmann); Department of English, University of Heidelberg (Marianne Hundt); Department of English, University of Mannheim (Manfred Krug).
Associate members:
- UK: Department of Linguistics and English Language, The University of Manchester (David Denison).
- Switzerland: Department of English, University of Zurich (Sebastian Hoffmann).
Acknowledgements
The consortium would like to thank the following student assistants who helped digitize additional materials: Taryn Hakala (Ann Arbor), Birgit Waibel (Freiburg), Stefanie Dose, Martin Schendzielorz and Stella Karaoulani (Heidelberg), Marianne Hintikka, Päivi Kilpinen and Tuula Chezek (Helsinki); Nuria Yáñez-Bouza (Manchester), collected header information in a database and helped with the re-labelling.
Genres, text types
The main aim for ARCHER 3.1 was to provide a maximally balanced corpus, with respect not only to genre, region, period and, crucially, also size. To this end, some texts from the original corpus (ARCHER 1) were shortened, some material collected during the first phase of collaboration (ARCHER 2) excluded and new texts digitized.
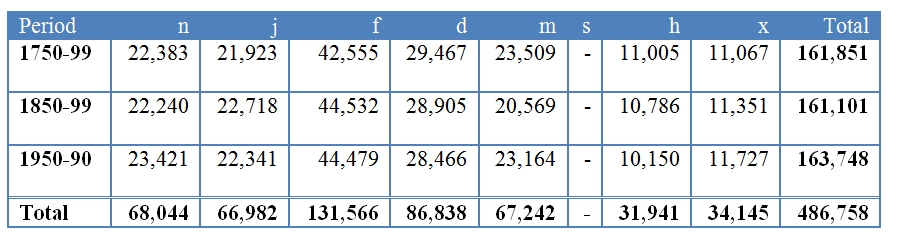
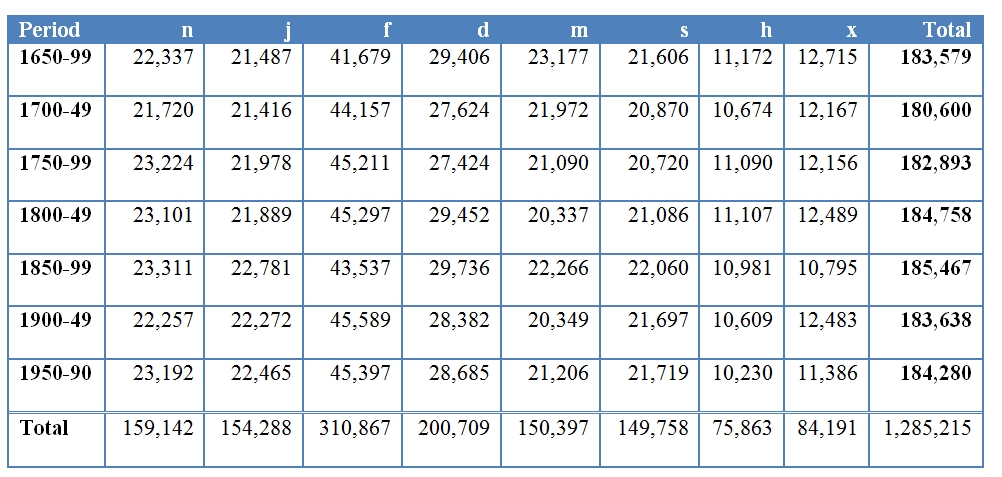
- Genres: d = drama, h = sermons, j = journal and diaries, m = medicine, n = news, s = science, x = letters, f = fiction (con = fictional conversation; pro = narrative prose)
- Regional variety: b = British, a = American
- Periods: 1650-99, 1700-49, 1750-99, 1800-49, 1850-99, 1900-49, 1950-90.
Size
CoRD_v3.1_American
CoRD_v3.1_British
Availability
The version of ARCHER 3.1 that was released to members of the consortium in 2006 is still available locally at the consortium universities.
|
|
|
